
Table of Contents:
From the very late 1990’s up until the time I retired, I worked in an office. I chose a different career path that involved sitting in front of a computer doing things with other computers and servers for the British Healthcare system: the NHS.
Post 3 covered the user account aspect of an IT department’s work in the NHS. User account management, the auditors and the IT department’s living nightmare: sysadmins.
This post covers backups and servers. Servers are the computers that hold all of the information and programmes, backups are copies of the data stored away in case anything goes wrong.
Backups
Backups were always a big thing. They still are, more so nowadays than when I started. If you recall the “incident” I related in Post 2 [post 2] about the virus, I had to recover the email server from a backup, so it was instilled in me at the outset of my journey through IT that backups were important. “Fortunately”, I had enough opportunity to prove that point many times over.
I say “fortunately” in inverted commas, as the recoveries could range from restoring a users word document that they’d accidentally deleted – a couple of minutes work, to recovering whole servers – a couple of days (or more) work.
Before the advent of integrated systems like VMWare or Hyper-V, backups were performed overnight, usually by dedicated backup servers and to tape-based media. Each physical server would have a backup agent installed on them that would talk to the backup server. The backup server would read the changed files for that day and stream them to tape. We did a full backup of the servers over the weekend (two days of lesser user activity) and did a differential (changed files since the last full backup) or incremental (changed files since the last backup) overnight. As the server estate grew, the backups became longer and longer, more tapes were used and more investment in both equipment and staff was required to keep the whole system running. Tapes were archived on a monthly, weekly and sometimes daily basis, so we always had multiple iterations of a server to choose from. Should we be unfortunate enough to catch a virus, or suffer a disaster, we could (in theory) recover back to before the virus had infected the server, or just before the disaster. You would suffer a slight loss of data, but that was accepted, as long as the virus was gone, or the disaster was averted.
Then VMWare and virtual server systems happened. This made backups much easier (and a lot quicker), as you could leverage the virtual systems snapshot service to do your backups. Backups became disk-based instead of tape-based, which made the whole process a lot quicker and easier to manage. The downside to that was it was quite expensive in terms of disk storage. Tapes were quite cheap in comparison and you could physically isolate a set of tapes if you needed to. For instance, a set of tapes would be physically taken offsite somewhere, to mitigate against any catastrophic disaster (like a bomb, a fire, or a major critical power outage). With disk-based storage, that wasn’t so easy. You had to buy additional storage and networks links to offsite buildings, in order to copy the backups. You also had to make extra sure that (as the offsite storage was network-attached) the storage was secure, physically, and especially from unauthorised network-based actors. You can’t “hack” a tape backup, if it’s 50 miles away locked in a fireproof safe. You can however, “hack” a disk-based backup if you had network access and the right credentials.
That was a difficult concept to relate to my management. The sales people (sigh) sold something called an “immutable backup”, meaning that it was marked as read-only and couldn’t be changed. If you could successfully hack into the immutable backup, you could inject a trojan so that when you recovered your “immutable” copy, you would recover the trojan with it. I argued that if it’s network-attached, it can be hacked and therefore changed. My solution was to go back to the old school method of taking a tape backup every now and again of that immutable backup system and taking it somewhere else. That way, you would ostensibly have a clean copy in case of a worst-case disaster.
When I retired in 2022, this hadn’t yet been implemented.
Virtual vs physical
Up until the point at which (a lot of) money became available in the Trust to purchase virtual server platforms, the Hospitals Trust used physical servers. Lots of them.
Let’s get physical
I mentioned in Post 1 concerning Trust Finance [How an IT Department is Financed in the NHS] that in the Hospitals Trust, the IT department didn’t fund any IT related equipment for the departmental users. This also applied to the servers: the Radiology department bought their own desktop workstations, phones and printers and paid the IT department a nominal fee to use centralised IT services, such as file and print servers (shared by the whole Trust). But if they wanted a bespoke server to run a certain software program, they would fund it themselves. Most of the time (but not all of the time!) we would have an input into what they bought, and provide advice on license costs for O/S (operating system) and A/V (anti-virus software). We would also insist on proper patch schedules (for Windows Updates and any firmware patches that may be required along the life of the server) and of course, backup requirements. The department would order and purchase, we would accept delivery, build (if required) load the appropriate A/V and backup agents etc. and that would be it. Generally that server sat there, doing its thing until it died, or a sysadmin killed it.
In terms of hardware support, power consumption, environmental requirements, this was seen as an expensive solution. For each physical server (and we had hundreds) you would have to either have warranty (if they were new), or some sort of hardware support if it failed. If it did break, we had to call engineers out to fix it. We generally paid for an external company to supply us with hardware support, with a four hour response period. You also had to cool the servers (some of the bigger ones were real heat blasters!) and you had to supply electricity to them. You also had to have network switches close by, so you could let them speak.
As they’re physical servers, when you specified them you would have to double-up on internal components, in case of hardware failure. So you’d specify twin cpu (processors), multiple sticks of RAM, twin power supplies, twin (or multiple) network ports. The disk arrays had to be redundant using industry standard RAID configurations, so that if a disk died the server would continue. (We used RAID 1 for system and RAID 5 for data, generally). Certain departments like the data processing teams would require speciality servers. Servers configured specifically to support database applications like SQL. These were very large, very power hungry beasts with multiple disk arrays configured in various versions of RAID to support SQL. They were expensive and the data team filled them up quickly!
This was the one and only scenario where the Hospitals Trust finance scenario worked to the IT department’s advantage. As the department that used the server had bought the server, if they wanted to expand or upgrade it, as long as they paid for it, we would do the work. Sometimes, the department in question “found some room”. LOL.
We had hundreds of physical servers, some of them 20+ years old, in a big air-conditioned server room. The room was full of server racks, and each rack full of servers. There were three UPS (uninterrupted power supplies) that would keep the servers running for about an hour. The whole site (as it’s a hospital) had multiple generators for backup power, that kicked in usually within a minute or two of a power failure. The generators were tested once a month on a Saturday morning – an event that at least one of the IT department had to attend to ensure everything went to plan. Server-wise it always went to plan (thankfully).
If a server were to fail, due to a hardware issue (or a catastrophic disk failure), then that server went out of action until someone fixed it. A physical server running a single program wasn’t usually an issue, unless it was a file or email server that was in constant use by many users. But because it was one server, it would only be one service. There was however, no failover. Only two systems in the entire Hospital Trust had a failover system, the X-Ray server in Radiology and the Patient Administration System (PAS) where a lot of patient test results and details were uploaded. For all of the other servers, the department to which it belonged would never fund additional servers for failover purposes.
Let’s not. No really, let’s not…
Get physical, that is.
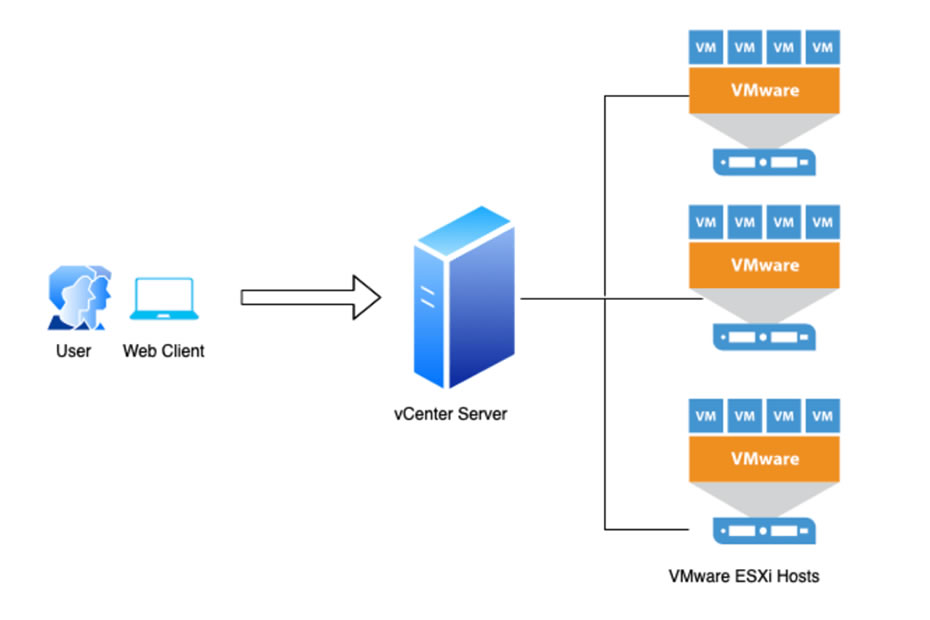
One day – and this must be close to sixteen years ago, just after the IT departments from the two Trusts merged, “it was decided” (which means that a Sales Rep had spoken to our management, and convinced them to spend some money) that we would install a virtual server system. We would invest in some blade servers (that ran the basic operating systems – VMWare) and some storage attached to it (for storing and running the virtual servers). Not only that, we would have two lots of it, one system would be live, the other a failover system. The premise was that the other system would match the live system and be positioned at a reasonable distance on site. We had a smaller server room that was down the other end, about half a mile away, so that was earmarked as the location for the failover system. Dedicated network links were installed to ensure there was uninterrupted traffic between the two systems and work began to build the system and then transfer the physical servers over to the virtual system.
This was an awful lot of work. We (and the network engineers) had to learn about chassis-based servers and attached storage really, really quickly. We had to learn about blade servers (we’d never had any previously) and there was another whole steep learning curve for VMWare. How it worked, what settings were there, how we migrated servers onto it, how we provisioned new ones, how we made sure that a recent copy was made to the failover.. the list went on and on.
Training, I hear you ask? Well, kind of. Not much money was available for training at that time. Our training had to come out of our budget, so at best we were allowed to send two (maximum) people on courses. The rest of us had to learn from them, or learn by experience. There was a lot of Googling! But we got there in the end. It wasn’t a totally smooth path to be sure, but we got there in the end.
So what did we gain?
There was so much talk around the reason we had individual physical servers was because if one stopped, it would affect small numbers of people. With a virtual system, if there was a hardware failure of that main system, all your servers would go down. But then, the failover would take over, wouldn’t it? Well, it would if all of the servers were copied over and the systems were big enough. Which of course, they weren’t. A select number of servers were chosen for failover and that’s how it stayed.
But what we did gain was the ability to remotely fix, maintain and backup servers. No longer did we have to physically go to a server to switch it on/off/reboot (although later on we had remote management connections in the backs of servers) , we could perform all that stuff remotely from the office next door (where there was tea and biscuits). We could use monitoring tools to check performances and adjust where necessary.
The biggest gain over the physical servers was the ability to snapshot. We could snapshot a server before performing updates, or testing new software. If it turned out to be unsatisfactory, you could rollback within a couple of minutes. If we wanted to migrate a physical server, we would have a base image already built for it (essentially, a snapshot) and then use it to recover (from physical backup) the server we wanted to migrate. If it went horribly wrong, you just started again. You wouldn’t have lost too much time. The snapshot system was the biggest lifesaver of all (especially for windows updates!).
As time went on, the demand for new servers increased manyfold. The finance model remained the same: the department still paid for the licensing and storage. We would charge them and the money was supposed to be reinvested in scaling the systems. This (of course) never happened, as the IT budget was so small, we had to use the money for other things. So the virtual systems became full, expansion was added (only when it had to be) and the virtual system lived on.
As time passed, almost all the physical servers disappeared. The networking on the virtual system could be segregated to support separate and isolated networks if necessary and many iterations of firewall, DMZ-based services and LAN-specific services were installed.
All good.
Or was it?
Summary
- Backups (copies of data or servers) are very important. Especially in the case of a disaster.
- Physical servers are good for some things, but quite resource intensive.
- Virtual servers are more cost effective and easier to manage. Better failover provision and backup utilities.
What we’ve covered so far…
(Post 1) How an IT Department is Financed in the NHS
(Post 2) Windows Updates
(Post 2) Network security
(Post 2) User device security
(Post 3) Account security
(Post 3) The administrators
(Post 3) User account management
(Post 3) The auditors
(Post 3) Sysadmins
(Post 4) Backups
(Post 4) Virtual vs physical